7.1 중첩 컬렉션
컬렉션마다 담을 수 있는 데이터의 종류가 다르다. 문자열은 문자열만을, 레인지는 정수만을, 튜플과 집합은 불변 데이터만 요소로 가진다. 그런데 리스트와 사전은 그 속에 담는 데이터의 유형을 가리지 않는다. 수, 문자열, 불리언, None, … 등 온갖 유형의 데이터를 섞어 담을 수 있다. 심지어 리스트 속에 리스트를, 사전 속에 사전을 담을 수도 있다. 리스트를 품은 사전을 품은 리스트도 문제 없다. 리스트와 사전의 이런 특징을 활용하면 블록 장난감을 조립하듯 데이터를 조립하여 현실의 다양한 대상을 데이터로 나타낼 수 있다.
7.1.1 리스트 중첩하기
리스트는 다른 리스트를 요소로 가질 수 있다.
코드 7-1 중첩 리스트 (nested_list1.py)
# 중첩 리스트
nested_list = [[1, 2, 3, 4], ['a', 'b', 'c', 'd'], [], [100, 200]]
# 중첩 리스트의 요소 읽기
nested_list[1][3] # 'd'
이렇게 리스트를 담은 리스트를 중첩 리스트라고 한다. 중첩 리스트를 이용해 다양한 구조를 표현할 수 있다. 데이터를 어떻게 담을지는 프로그래머가 정하기 나름이다. 몇 가지 예를 보자.
코드 7-2 중첩 리스트로 다양한 데이터 나타내기 (nested_list2.py)
# 좌표평면 위의 도형을 나타내는 꼭지점의 좌표들
coordinates = [[0, 0], [0, 9], [8, 9], [8, 0]]
# 체스판에 놓인 말들
pieces = [
['A', 8, 'black', '룩'],
['D', 7, 'black', '킹'],
['C', 4, 'white', '비숍'],
['E', 1, 'white', '킹'],
]
# 서가에 보관해 둔 도서 정보
books = [
['파이썬으로 시작하는 컴퓨터 과학 입문', ['존 M. 젤']],
['파이썬을 활용한 데이터 길들이기', ['J. 카질', 'K. 자멀']],
['HTTP 완벽 가이드', ['D. 고울리', 'B. 토티', 'M. 세이어', 'S. 레디']],
]
coordinates는 네 개의 요소를 갖는 리스트다. 리스트의 각 요소는 좌표평면 위의 점을 가리키는 좌표인데, 각각 두 개의 요소를 갖는 리스트다. 좌표의 첫번째 요소는 x 축의 위치, 두번째 요소는 y 축의 위치다.pieces는 체스판 위의 말들을 나타낸다. 한 행에 작성하기에는 너무 길어, 줄바꿈과 들여쓰기를 이용해 한 행에 요소 하나씩 써 넣었다. 각 요소는 체스 말 하나를 나타내는 네 개의 정보를 담은 리스트다. 첫번째 요소와 두번째 요소는 체스 말이 놓인 위치이고, 세번째 요소는 체스 말의 색(진영), 마지막 요소는 체스 말의 역할이다.books는 서가에 보관한 도서의 정보를 기록한 것이다. 리스트의 요소 하나하나는 책을 나타내는 리스트다. 책 정보의 첫번째 요소는 제목, 두번째 요소는 저자 리스트다. 저자가 여러명인 경우도 있어 리스트에 담아야 한다. 이 경우처럼 리스트 속의 리스트 속에 또 리스트를 넣어도 문제 없다.
대상에서 어떤 특성을 선택할 것인가
사물과 현상을 데이터로 표현하려면 대상을 추상화해야 한다. 대상의 모든 특성을 1:1로 정확히 옮기는 일은 불가능하다. 대상에서 프로그램에 필요한 정보만 골라내야 한다. 예컨대 체스판의 말에는 재질, 무게, 크기, 사용된 횟수, 자석이 달려있는지 등의 요소도 있다. 하지만 이런 정보는 체스 프로그램에서 불필요하여 포함시키지 않았다. 반면, 말의 위치, 색(진영), 역할은 체스 게임에서 본질적인 요소이므로 꼭 필요하다. 선택해야 하는 정보는 프로그램의 목적에 따라 다르다. 체스 말을 판매하는 쇼핑몰 웹사이트 프로그램이라면 체스 말의 가격이 더 중요한 정보가 될 것이다.
데이터를 설계하는 방법은 다양하다
동일한 대상이라도 데이터로 나타내는 방법은 다를 수 있다. 다음은 코드 7-2에서 표현한 ‘체스판에 놓인 말들’을 다른 방법으로 나타낸 것이다.
코드 7-3 체스판 전체를 나타낸 중첩 리스트
# 체스판(그리고 그 위에 놓인 말들)
board = [
[['black', '룩'], None, None, None, None, None, None, None],
[None, None, None, ['black', '킹'], None, None, None, None],
[None, None, None, None, None, None, None, None],
[None, None, None, None, None, None, None, None],
[None, None, ['white', '비숍'], None, None, None, None, None],
[None, None, None, None, None, None, None, None],
[None, None, None, None, None, None, None, None],
[None, None, None, None, ['white', '킹'], None, None, None],
]
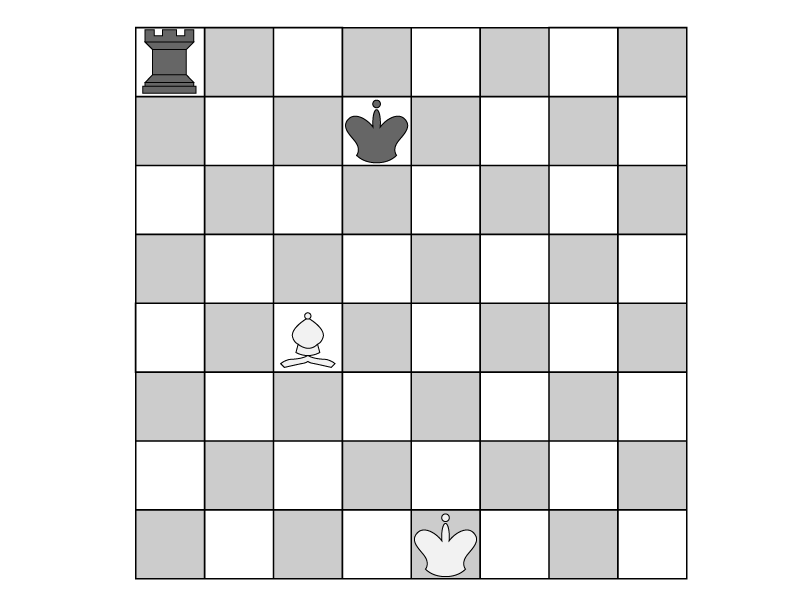
그림 7-1 체스판
위의 board는 체스판 전체에 놓인 체스 말들을 나타내는 리스트로, 마치 그림 7-1의 체스판을 그대로 옮겨 그린 듯한 형태다. 리스트 안의 각 요소는 체스판의 한 행을 나타내는 리스트이고, 그 리스트 각각은 한 행 안의 칸들을 표현하고 있다. 말이 놓여있지 않은 곳은 None이고, 말이 놓여있는 곳은 체스 말의 정보가 담겨 있다. 말 하나를 나타내는 정보에서 위치 정보는 빠졌다. 리스트 내의 요소 위치가 말의 위치를 나타내기 때문이다.
코드 7-3의 board와 코드 7-2의 pieces는 동일한 체스판을 표현하고 있다. 그런데 코드 7-2는 말에, 코드 7-3은 체스판 전체에 초점을 맞췄다. 데이터를 어떻게 구조화하는가에 따라 데이터를 사용하는 방법과 프로그램을 작성하는 방법도 달라진다. 프로그래밍 할 때는 데이터를 나타내는 데 어떤 방식을 사용할 것인지 잘 판단해야 한다. 이런 능력은 프로그래밍을 경험을 쌓으며 익힐 수 있다.
중첩 리스트의 요소에 접근하기
중첩 리스트의 요소에 접근할 때는 인덱싱 연산자([, ])를 연달아 쓰면 된다.
코드 7-4 중첩된 리스트의 요소에 접근하기
>>> nested_list = [[1, 2, 3], [4, [5, 6, [7, 8]]]]
>>> nested_list[0] # ❶
[1, 2, 3]
>>> nested_list[0][1] # ❷
2
>>> nested_list[1]
[4, [5, 6, [7, 8]]]
>>> nested_list[1][1]
[5, 6, [7, 8]]
>>> nested_list[1][1][2] # ❸
[7, 8]
>>> nested_list[1][1][2][0] # ❹
7
위 코드를 대화식 셸에서 직접 실행해보기 바란다. 바깥쪽 리스트의 요소에 접근하는 ❶을 실행하면 안쪽 리스트를 구할 수 있다. ❷는 이 리스트에 다시 인덱싱을 수행하여 안쪽 리스트의 요소를 구한 것이다. ❸, ❹와 같이 더욱 깊이 중첩된 리스트의 요소도 문제 없이 접근할 수 있다.
연습문제
연습문제 7-1 중첩 리스트로 데이터 나타내기
다음은 9월 1일의 지역별 날씨를 나타내는 정보다. 이 정보를 중첩 리스트를 사용해 나타내 보아라.
| 날짜 | 지역 | 날씨 | 기온 | 습도 | 강수확률 |
|---|---|---|---|---|---|
| 9월 1일 | 경기 | 맑음 | 27.2 | 0.4 | 0.1 |
| 9월 1일 | 강원 | 맑음 | 23.6 | 0.6 | 0.1 |
| 9월 1일 | 충청 | 맑음 | 24.4 | 0.35 | 0.1 |
| 9월 1일 | 경상 | 맑음 | 26 | 0.55 | 0.1 |
| 9월 1일 | 전라 | 맑음 | 27 | 0.4 | 0 |
| 9월 1일 | 제주 | 구름 조금 | 26.4 | 0.45 | 0.1 |
7.1.2 사전과 리스트 중첩하기
리스트로 대상을 나타내면 각 요소가 대상의 어떤 정보를 나타내는 것인지 알기 어렵다. 예를 들어, 좌표 [8, 9]의 첫 번째 요소 8은 x 축의 위치일까, y 축의 위치일까? 또 체스 말 하나를 나타내는 리스트 ['C', 4, 'white', '비숍']에서 두 번째 요소 4는 정말 위치를 의미하는 것일까? 이 말로 다른 말을 잡은 횟수를 뜻하는 것은 아닐까? 이처럼 모호한 점이 많다.
리스트 대신 사전을 이용하면 키의 이름으로 데이터의 의미를 표시할 수 있다. 다음은 코드 7-2에서 나타낸 각종 정보를 리스트와 사전을 함께 사용하도록 수정한 것이다.
코드 7-5 리스트와 사전을 중첩해 다양한 데이터 나타내기
# 좌표평면 위의 도형을 나타내는 꼭지점의 좌표들
coordinates = [
{'x': 0, 'y': 0},
{'x': 0, 'y': 9},
{'x': 8, 'y': 9},
{'x': 8, 'y': 0},
]
# 체스판에 놓인 말들
pieces = [
{'x': 'A', 'y': '8', 'color': 'black', 'role': '룩'},
{'x': 'D', 'y': '7', 'color': 'black', 'role': '킹'},
{'x': 'C', 'y': '4', 'color': 'white', 'role': '비숍'},
{'x': 'E', 'y': '1', 'color': 'white', 'role': '킹'},
]
# 서가에 보관해 둔 도서 정보
books = [
{'title': '파이썬으로 시작하는 컴퓨터 과학 입문',
'authors': ['존 M. 젤']},
{'title': '파이썬을 활용한 데이터 길들이기',
'authors': ['J. 카질', 'K. 자멀']},
{'title': 'HTTP 완벽 가이드',
'authors': ['D. 고울리', 'B. 토티', 'M. 세이어', 'S. 레디']},
]
coordinates리스트의 요소 좌표들을 리스트 대신 사전으로 표현했다. 좌표에서 x가 먼저인지 y가 먼저인지 생각하지 않고도 x 축의 위치와 y 축의 위치를 정확히 구별할 수 있다.pieces의 요소 체스 말들을 사전으로 표현했다. x, y는 좌표, color는 말의 색, role은 말의 역할이란 것을 쉽게 알 수 있다.books의 도서도 사전으로 나타내면 알기 쉽다. title은 제목, authors는 저자들이며, 특히 복수형 이름 덕분에 여러 명의 저자를 담은 리스트가 데이터로 들어있을 것임을 짐작할 수 있다.
이처럼 여러 개의 개체를 리스트에 모으되, 각 개체는 사전으로 표현하는 것이 유리하다.
개념 정리
- 리스트와 사전을 중첩해 복잡한 형태의 정보를 표현할 수 있다.
- 한 개체의 여러 가지 특성을 표현할 때는 사전이 유리하다.
- 여러 개의 개체를 하나로 묶을 때는 리스트가 유리하다.
연습문제
연습문제 7-2 리스트와 사전을 이용해 데이터 나타내기
연습문제 7-1에서 정의한 날씨 정보를 리스트와 사전을 이용해 다시 정의해 보아라.
7.1.3 양이 많은 데이터를 쉽게 나타내고 읽는 방법
리스트와 사전을 중첩하면 데이터를 나타낸 코드가 점점 복잡해지고 길이도 길어서 읽기가 힘들어진다. 개행과 들여쓰기를 적절히 활용하면 보기 좋은 코드를 작성할 수 있다. 예를 들어 아래의 세 코드는 모두 동일한 데이터를 나타낸 것이지만 작성된 스타일이 다르다.
코드 7-6 데이터를 표기하는 코딩 스타일들
# 한 행에 걸쳐 모두 표기한 스타일
books1 = [{'title': '파이썬으로 시작하는 컴퓨터 과학 입문', 'authors': ['존 M. 젤']}, {'title': '파이썬을 활용한 데이터 길들이기', 'authors': ['J. 카질', 'K. 자멀']}, {'title': 'HTTP 완벽 가이드', 'authors': ['D. 고울리', 'B. 토티', 'M. 세이어', 'S. 레디']}]
# 리스트를 여러 행에 걸쳐 작성하기
books2 = [
{'title': '파이썬으로 시작하는 컴퓨터 과학 입문', 'authors': ['존 M. 젤']},
{'title': '파이썬을 활용한 데이터 길들이기', 'authors': ['J. 카질', 'K. 자멀']},
{'title': 'HTTP 완벽 가이드', 'authors': ['D. 고울리', 'B. 토티', 'M. 세이어', 'S. 레디']},
]
# 리스트와 리스트에 포함된 사전을 여러 행으로 나누어 작성하기
books3 = [
{
'title': '파이썬으로 시작하는 컴퓨터 과학 입문',
'authors': ['존 M. 젤']
},
{
'title': '파이썬을 활용한 데이터 길들이기',
'authors': ['J. 카질', 'K. 자멀']
},
{
'title': 'HTTP 완벽 가이드',
'authors': ['D. 고울리', 'B. 토티', 'M. 세이어', 'S. 레디']
},
]
books1은 한 행에 모든 내용을 넣는 방식이다. 이런 방식은 눈으로 봤을 때는 데이터의 내용을 파악하기가 힘들다.books2는 리스트를 여러 행에 걸쳐 작성했다. 리스트의 각각의 요소는 한 행에 하나씩, 한 단계씩 들여쓰기되어 작성되었다. 다만 요소(사전)의 크기가 크다보니 한 행에 표시되는 코드의 양을 줄이기 위해 한 번씩 개행을 했다.books3은 리스트와 사전을 모두 여러 행에 걸쳐 작성한 것이다. 리스트의 요소를 한 단계씩 개행했고, 사전의 키-값 쌍도 한 단계씩 더 개행하여 나타냈다.
books2와 books3의 스타일처럼 컬렉션의 중첩 구조를 드러내는 스타일을 추천한다. books1의 스타일은 구조를 알아보기 불편해 좋지 않다.
pprint로 복잡한 데이터를 구조적으로 출력하기
그런데 개행과 들여쓰기를 이용해 데이터를 표기하더라도, 파이썬이 여러분에게 데이터를 보여줄 때는 한 행에 모두 모아서 보여준다는 문제가 있다. 다음은 코드 7-6에서 정의한 books3를 대화식 셸에서 출력해 본 것이다.
코드 7-7 컬렉션을 출력했을 때
>>> print(books3)
[{'title': '파이썬으로 시작하는 컴퓨터 과학 입문', 'authors': ['존 M. 젤']}, {'title': '파이썬을 활용한 데이터 길들이기', 'authors': ['J. 카질', 'K. 자멀']}, {'title': 'HTTP 완벽 가이드', 'authors': ['D. 고울리', 'B. 토티', 'M. 세이어', 'S. 레디']}]
파이썬 인터프리터가 코드를 해석한 후에는 데이터만 남고 개행·들여쓰기 등의 코드 스타일은 버려진다. 따라서 코드 7-6의 books1, books2, books3은 코드 스타일과 관계없이 똑같은 내용으로 저장되며, 그것을 출력하면 파이썬의 기본 출력 방식(한 행에 모두 표시)으로 데이터가 출력된다.
데이터를 좀 더 쉽게 알아보고 싶다면 pprint() 함수(pretty print를 의미)를 사용한다.
코드 7-8 pprint()로 데이터 구초 출력하기
>>> import pprint # pprint() 함수가 들어있는 모듈을 임포트
>>> pprint.pprint(books3)
[{'authors': ['존 M. 젤'], 'title': '파이썬으로 시작하는 컴퓨터 과학 입문'},
{'authors': ['J. 카질', 'K. 자멀'], 'title': '파이썬을 활용한 데이터 길들이기'},
{'authors': ['D. 고울리', 'B. 토티', 'M. 세이어', 'S. 레디'], 'title': 'HTTP 완벽 가이드'}]
pprint() 함수를 이용하면 컬렉션의 요소를 적절히 개행하고 들여쓰기하여 보기 좋게 출력해 준다. 복잡한 컬렉션을 화면에 출력해 확인할 때 유용하다.
연습문제
연습문제 7-3 데이터 코딩 스타일 다듬기
연습문제 7-2에서 정의한 날씨 정보를 개행과 들여쓰기를 이용해 좀 더 보기좋게 다듬어 보아라. 이미 스타일이 괜찮다면 그대로 두어도 좋다. 다 다듬은 후에는 pprint() 함수에 전달해 출력해 보아라. 그 후, 여러분의 스타일과 pprint() 함수의 스타일을 비교해 보고, 두 스타일의 장단점을 설명해 보아라.
댓글 남기기