5.2 시퀀스
- 5.2.1 순서가 있는 데이터 구조
- 5.2.2 리스트
- 5.2.3 시퀀스 연산
- 5.2.4 시퀀스 조작 메서드
- 5.2.5 리스트로 연락처 관리하기
- 5.2.6 튜플
- 5.2.7 레인지
- 5.2.8 문자열은 시퀀스다
“1번 버스”, “전철역 2번 출구”, “3번 학생”, “4 페이지” 등, 우리는 어떤 대상에 번호를 붙여 관리하기를 좋아한다. 관리할 대상이 많더라도 순서를 정해 차례대로 나열해 두면, 그 가운데 하나를 콕 집어내기도 쉽고, 빠트리지 않고 하나씩 살펴보기도 좋다. 순서를 정해 두는 것은 데이터 관리에도 도움이 된다.
그림 5-1 순서를 정해 둔 사물
5.2.1 순서가 있는 데이터 구조
시퀀스(sequence)는 데이터에 순서(번호)를 붙여 나열한 것이다. 다음은 장바구니에 담을 물건을 메모한 목록이다.
- 아이스크림, 커피, 설탕, 쿠키, 우유
이 목록은 일종의 시퀀스다. 시퀀스에서는 순서로 요소를 가리킬 수 있다. 첫 번째 요소는 아이스크림, 두 번째는 커피, 마지막은 우유다. “네 번째 데이터가 무엇이냐”라는 질문에 “쿠키”라고 답하는 것도 가능하다. 이 예처럼 시퀀스는 데이터를 하나씩 순서대로 나열한 것으로, 한 위치를 가리켜 데이터를 집어내는 것도 가능하다.
시퀀스의 특징
- 데이터를 순서대로 하나씩 나열하여 나타낸 데이터 구조다.
- 특정 위치(~번째)의 데이터를 가리킬 수 있다.
나열과 정렬은 다르다
시퀀스의 데이터에 순서가 있다는 말을 데이터가 정렬되었다는 뜻으로 오해하면 안 된다. 날짜를 나열한 다음 시퀀스를 생각해 보자.
- 2018-02-15, 2018-02-16, 2018-02-17
이 시퀀스에서 마지막 요소인 ‘2018-02-17’ 다음에 어떤 데이터를 추가한다고 할 때, 그 데이터는 무엇일까? 시퀀스에서 날짜가 하루씩 증가하고 있으므로 그 다음날인 ‘2018-02-18’일까? 만약 이 시퀀스가 2018년의 공휴일 목록을 나타내는 것이라면, 그 다음 공휴일인 ‘2018-03-01’이 맞을지도 모르겠다.
하지만 시퀀스 속의 데이터에 어떤 정렬 규칙이 반드시 있어야 하는 것은 아니다. 위 날짜 시퀀스 뒤에 ‘1999-12-31’ 같은 과거의 날짜가 들어갈 수도 있고, 심지어 날짜가 아니라 ‘아이스크림!’ 같은 데이터가 들어갈 수도 있다. 시퀀스에 담은 데이터의 순서란 데이터의 나열 순서일 뿐이다. 순서가 있다는 것과 정렬되었다는 것은 의미가 다르다. 시퀀스의 데이터는 어떤 기준에 따라 정렬되었을 수도 있고 무작위로 나열되었을 수도 있다. 어쨌든 데이터를 관리하기 위한 순서(번호)는 반드시 존재한다.
시퀀스 컬렉션의 종류
파이썬은 리스트(list), 튜플(tuple), 레인지(range), 문자열(string) 등이 여러 가지 시퀀스 컬렉션을 제공한다. 이 시퀀스들은 데이터를 저장하고 표현하는 방식이 서로 다르지만, 요소에 번호를 붙여 순서대로 관리한다는 점은 모두 똑같다.
5.2.2 리스트
리스트는 목록이라는 뜻으로, 다양한 데이터를 담을 수 있고 내용을 변경할 수 있는 시퀀스다. 파이썬의 시퀀스 중에서 가장 많이 사용되며 가장 대표적이다.
리스트 표현하기
리스트는 대괄호([, ])를 이용해 표현할 수 있다. 다음은 몇 가지 리스트의 예다.
코드 5-3 리스트 표현하기
# ❶ 빈 리스트
[]
# ❷ 여러 유형의 데이터로 구성된 리스트
[10, 'hi', True]
# ❸ 숫자로 구성된 리스트
[1, 2, 3, 4]
대괄호는 리스트를 의미하며, 대괄호 안에는 원하는 만큼 요소를 입력할 수 있다. 이 때 요소와 요소는 콤마(,)로 구분해주면 된다. ❶처럼 아무 요소도 갖지 못한 빈 리스트도 리스트다. ❷처럼, 리스트에는 어떤 데이터 유형이든 자유롭게 담을 수 있고 여러 데이터 유형을 뒤섞을 수도 있다. 그렇지만 ❸과 같이 동일한 유형의 데이터를 담는 경우가 대부분이다.
리스트에 이름 붙이기
원자 데이터와 마찬가지로, 컬렉션도 변수에 대입하여 이름을 붙여둘 수 있다. 이어질 실습을 위해, 대화식 셸을 실행하고 다음 리스트를 변수로 대입해 두자.
코드 5-4 리스트를 변수에 대입하기
>>> number_list = [1, 2, 3, 4, 5]
>>> alphabet_list = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
컬렉션의 이름 짓기
컬렉션의 이름을 지을 때는 원자 데이터의 이름과 구별되도록 하는 것이 좋다. 복수형 이름이나 컬렉션의 종류를 접미사로 붙이는 방식이 많이 사용된다.
- 복수형 이름:
numbers,names등- 컬렉션의 종류를 접미사로 붙이기:
_list,_dict,_set등
연습문제
연습문제 5-1 수 리스트 정의하기
0 이상이고 100 미만인 모든 8의 배수의 리스트 multiples_of_8_list를 정의하라.
힌트: 요소를 직접 계산해서 나열하기가 불편할 것이다. 이후에 배울 레인지를 사용하면 그런 불편이 줄어든다.
5.2.3 시퀀스 연산
앞에서 정의한 두 개의 리스트 number_list, alphabet_list를 조작하며 시퀀스 연산을 알아볼 것이다.
정수, 실수, 복소수 데이터 유형은 모두 수치 데이터이기 때문에 수치 연산을 대부분 공유한다. 이와 마찬가지로 리스트, 튜플, 레인지, 문자열 등 시퀀스들은 시퀀스 연산을 공유한다. 여기서는 리스트를 예로 들어 설명하지만, 이후에 배울 다른 시퀀스에서도 마찬가지로 사용할 수 있다.
소속 검사하기
시퀀스에 어떤 요소가 들어 있는지 확인하고 싶을 때는 in 연산자를 사용한다. 반대로 요소가 없음을 검사하려면 not in을 사용한다.
코드 5-5 소속 검사
>>> 3 in number_list # number_list에 3이 들어 있는지 검사
True
>>> 'z' in alphabet_list # alphabet_list에 'z'가 들어 있는지 검사
False
>>> 0 not in number_list # number_list에 0이 안 들어 있는지 검사
True
길이 세기
시퀀스의 길이를 조사할 때는 len() 함수를 사용한다. 이 때 길이란 시퀀스에 들어 있는 요소의 개수를 뜻한다.
코드 5-6 시퀀스 길이 세기
>>> len(number_list)
5
>>> len(alphabet_list)
8
연결과 반복
덧셈 연산자와 곱셈 연산자를 사용해 시퀀스 데이터를 연결하거나 반복할 수 있다.
코드 5-7 시퀀스 연결과 반복
>>> number_list + alphabet_list # 리스트 연결하기
[1, 2, 3, 4, 5, 'a', 'b', 'c', 'd', 'e']
>>> number_list * 2 # 리스트 반복하기
[1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
어디서 본 것 같은데…
길이 세기, 연결과 반복 연산은 4.3절에서 소개한 것과 동일하다. 문자열도 시퀀스 컬렉션의 한 종류이므로 시퀀스 연산을 사용한다.
인덱싱: 특정 위치의 요소 가리키기
컬렉션에 들어 있는 특정 요소를 가리키는 것을 인덱싱(indexing) 연산이라고 한다. 변수의 이름으로 변수의 값을 가리키는 것처럼, 컬렉션의 요소를 가리켜서 그 요소를 구하거나 다른 값으로 수정하는 등의 작업을 할 수 있다.
인덱싱 연산을 표기할 때는 컬렉션[위치]와 같이 컬렉션 변수의 오른쪽에 인덱싱 연산자([])를 써서 나타낸다. 대괄호는 리스트를 작성할 때도 쓰는데, 인덱싱 연산자로 쓰일 때는 시퀀스의 바로 오른쪽에 표기하므로 구별할 수 있다. 예를 들어, ['a', 'b', 'c'][1] 에서 ['a', 'b', 'c']는 리스트이고 [1]은 인덱스 연산이다.
시퀀스에서는 구하려는 요소의 인덱스(index, 항목의 위치 번호)를 이용해 인덱싱한다. 다음 예는 alphabet_list에서 1번 위치와 -1번 위치의 데이터를 구하는 예다.
코드 5-8 리스트의 요소 가리키기
>>> alphabet_list[1] # 1번 위치(두 번째)의 요소 가리키기
'b'
>>> alphabet_list[-1] # -1번 위치(뒤에서 첫 번째)의 요소 가리키기
'h'
파이썬에서는 첫 번째 요소를 0번으로 하여 순서대로 번호를 매긴다. 0번 위치가 첫 번째 요소의 위치이고, 1번 위치는 두번째 요소의 위치다. 따라서 alphabet_list[1]의 평가 결과는 ['a', 'b', 'c', ... 'h']의 두 번째 요소인 'b'가 되었다. 또한,alphabet_list[-1]과 같이 음수를 인덱스로 지정할 수도 있다. -1번 위치란 뒤에서부터 첫 번째 위치, 즉 마지막 위치를 뜻한다. -0과 0은 구별되지 않으므로 뒤에서부터 셀 때는 -1이 첫 번째 위치다.
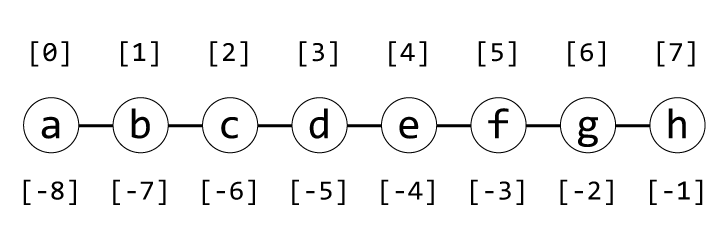
그림 5-2 시퀀스에서의 데이터 순서
리스트는 저장된 값을 수정할 수 있다. 다음과 같이 인덱싱 연산을 이용해 특정 위치의 값을 교체할 수 있다.
코드 5-9 리스트의 요소 교체하기
>>> number_list[2] = -3 # 2번 위치(세번째) 요소를 교체
>>> number_list
[1, 2, -3, 4, 5]
가변 데이터와 불변 데이터
데이터 유형은 내용의 수정이 허용되는 것과 금지되는 것으로도 분류가 된다.
리스트는 값을 변경할 수 있는 가변(mutable) 데이터다.
number_list[2] = '-3'처럼 내용을 수정하는 연산이 가능하다.반면, 값을 변경할 수 없는 불변(immutable) 데이터도 있다. 불변 데이터에는 수, 튜플, 문자열 등이 있다.
number = 10을 저장한 후number += 1을 실행하면number의 값은11로 변한다. 하지만number가 가리키는 값이 바뀌었을 뿐,10이11이 된 것은 아니다.
슬라이싱: 범위를 정해 선택하기
인덱싱 연산은 단 하나의 요소만을 가리키지만, 슬라이싱(slicing) 연산을 이용하면 일정한 범위의 요소를 선택할 수 있다. 슬라이싱 연산으로 선택할 범위를 지정할 때는 대괄호 속에 속에 콜론(:) 연산자로 시작 위치와 종료 위치를 구분해 표기한다. 이 때, 시작 위치는 범위에 포함되지만 종료 위치는 포함되지 않는다. (시작 위치 <= 범위 < 종료 위치)
코드 5-10 슬라이싱 범위 지정
>>> alphabet_list[2:6] # 2 이상 6 미만 위치의 범위 선택
['c', 'd', 'e', 'f']
>>> alphabet_list[:3] # 3 미만 위치의 범위 선택 (시작 위치 생략)
['a', 'b', 'c']
>>> alphabet_list[5:] # 5 이상 위치의 범위 선택 (종료 위치 생략)
['f', 'g', 'h']
>>> alphabet_list[:] # 전체 범위 선택 (시작, 종료 위치 모두 생략)
['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
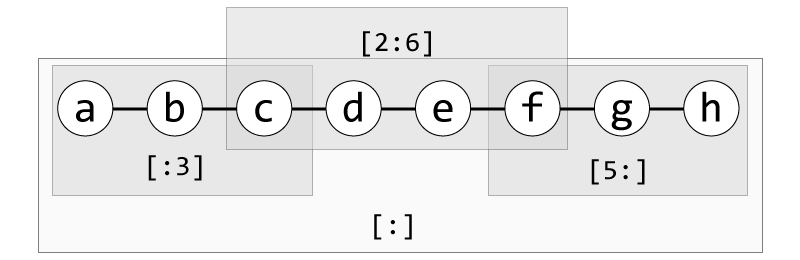
그림 5-3 슬라이싱 범위 지정
코드 5-10에서 보듯 시작 위치와 종료 위치를 생략할 수도 있다. 시작 위치를 생략하면 처음부터, 종료 위치를 생략하면 마지막까지를 의미한다. 둘다 생략하면 시퀀스의 전체 범위가 선택된다.
슬라이싱 연산을 표현할 때 대괄호 안에 세 번째 값으로 간격(step)을 지정할 수 있다. 간격은 몇 번째 요소마다 하나씩 선택할 것인지를 뜻한다. 예를 들어 간격을 2로 지정하면 두 요소마다 하나씩 선택한다. 간격이 음수이면 뒤에서부터 역방향으로 선택한다.
코드 5-11 간격을 지정하여 슬라이싱하기
>>> alphabet_list[::2] # 전체 범위에서 두 요소마다 하나씩 선택
['a', 'c', 'e', 'g']
>>> alphabet_list[1::2] # 1 이상의 범위에서 두 요소마다 하나씩 선택
['b', 'd', 'f', 'h']
>>> alphabet_list[::-1] # 전체 범위에서 뒤에서부터 한 요소마다 하나씩 선택
['h', 'g', 'f', 'e', 'd', 'c', 'b', 'a']
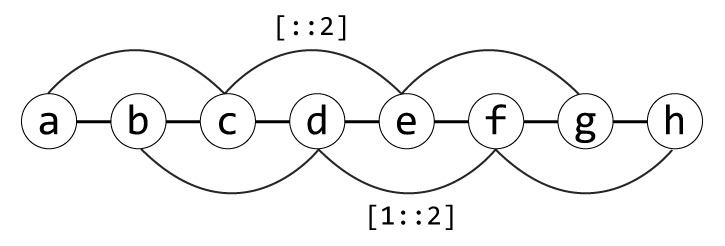
그림 5-4 간격을 지정하여 슬라이싱하기
시퀀스 복제
슬라이싱 연산으로 구한 시퀀스는 원본 시퀀스의 일부가 아니라 독립적인 사본이다. 시퀀스가 복제된다는 것이 무슨 뜻인지 실험을 통해 확인해보자.
코드 5-12 복제된 시퀀스는 원본과 독립적이다
>>> original_list = ['a', 'b', 'c', 'd']
>>> copied_list = original_list[:] # 리스트 복제하기
>>> copied_list == original_list # 두 리스트의 내용은 동일하다
True
>>> copied_list[0] = 'A' # 사본의 요소 하나를 변경하면...
>>> copied_list # 사본의 내용은 수정되었다
['A', 'b', 'c', 'd']
>>> original_list # 그러나 원본의 내용은 수정되지 않았다
['a', 'b', 'c', 'd']
>>> copied_list == original_list # 이제 두 리스트의 내용이 다르다
False
슬라이싱 연산을 수행하여 시퀀스를 복제한 뒤, 사본을 수정하더라도 원본은 수정되지 않는다는 점을 알 수 있다. 반면, 시퀀스를 다른 변수에 단순히 대입할 경우에는 이름만 두 개일 뿐, 두 이름이 가리키는 시퀀스는 동일하다.
코드 5-13 이름만 다를 뿐 동일한 시퀀스
>>> assigned_list = original_list # 리스트를 다른 변수에 대입
>>> assigned_list[1] = 'B' # 대입한 리스트를 수정
>>> original_list # 원본 리스트의 내용이 변경되었다
['a', 'B', 'c', 'd']
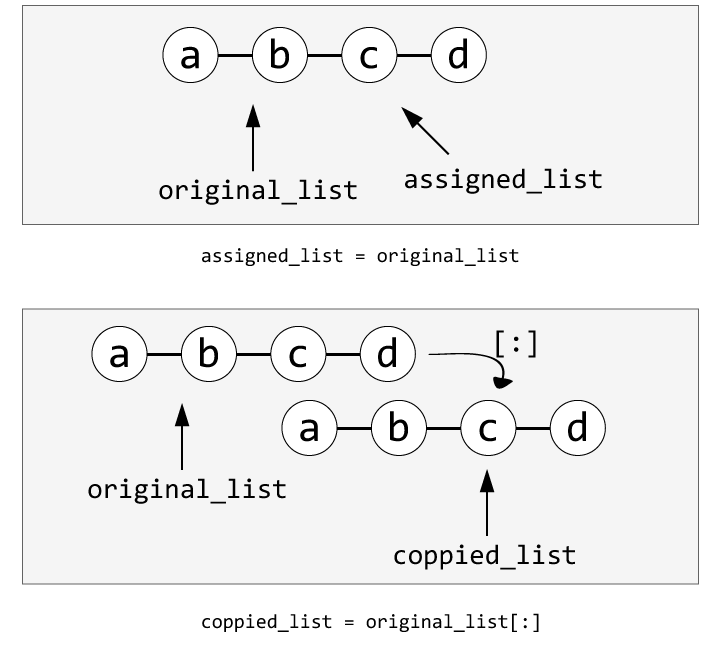
그림 5-5 시퀀스 복제와 단순 대입의 비교
범위를 지정하여 수정하기
시퀀스에서 슬라이싱 표현으로 선택한 범위에 새로운 값을 대입하면 그 범위의 요소들을 다른 내용으로 교체할 수 있다. 이 경우에는 복제본이 생성되는 것이 아니라 원본 시퀀스가 수정된다. 선택한 범위의 크기와 새로운 내용의 크기는 달라도 된다.
코드 5-14 범위를 지정하여 수정하기
>>> number_list[1:3] = [200, 300] # 1 - 3 위치를 선택해 새로운 내용으로 수정
>>> number_list
[1, 200, 300, 4, 5]
통계 함수
sum() 함수를 사용하면 시퀀스의 모든 요소의 합을 구할 수 있다.
코드 5-15 sum으로 모든 요소의 합 구하기
>>> sum(number_list)
510
min() 함수와 max() 함수를 사용해 시퀀스에 포함된 최소 요소와 최대 요소를 구할 수 있다.
코드 5-16 min, max로 최소, 최대 요소 구하기
>>> min(number_list) # 가장 작은 요소
1
>>> max(number_list) # 가장 큰 요소
300
>>> min(['가', '나', '다') # 가장 작은 요소 (가나다순 비교)
'가'
>>> max(['가', '나', '다']) # 가장 큰 요소 (가나다순 비교)
'다'
물론, 시퀀스에 포함된 요소는 크기를 서로 비교할 수 있는 대상이어야 한다. 그렇지 않을 경우에는 오류가 발생한다.
코드 5-17 잘못된 크기 비교
>>> min([1, 2, 3, 'a']) # 잘못된 크기 비교
TypeError: '<' not supported between instances of 'str' and 'int'
지금까지 소개한 시퀀스 연산은 다양한 시퀀스에서 공통적으로 사용할 수 있다. 길이를 세는 len(), 인덱싱 연산, 슬라이싱 연산은 매우 자주 사용되는 연산이므로 반드시 코드를 따라 입력해 보고 익혀 두는 것이 좋다.
연습문제
연습문제 5-2 가운데 요소 찾기
center() 함수를 정의하라. 이 함수는 시퀀스를 하나 입력받아, 시퀀스에서 가운데에 있는 요소를 반환한다. 단, 이 함수에는 홀수 개의 요소를 가지는 시퀀스만을 입력하기로 약속한다. 다음은 함수를 호출한 예다.
>>> center(['가', '나', '다', '라', '마'])
'다'
>>> center([2, 4, 8, 16, 32])
8
연습문제 5-3 시퀀스 거울
mirror() 함수를 정의하라. 이 함수는 시퀀스를 하나 입력받아 그 시퀀스를 뒤집은 시퀀스를 원본에 덧붙여 반환한다. 단, 원본 시퀀스의 마지막 요소는 덧붙이지 않는다. 다음은 함수를 호출한 예다.
>>> mirror([1, 2, 3])
[1, 2, 3, 2, 1]
>>> mirror(['가', '져', '가', '라'])
['가', '져', '가', '라', '가', '져', '가']
힌트: 슬라이싱 연산으로 순서를 뒤집은 리스트를 먼저 만들자.
연습문제 5-4 최대최솟값
minmax() 함수를 정의하라. 이 함수는 전달받은 시퀀스의 최솟값과 최댓값을 리스트에 담아 반환한다. 다음은 함수를 호출한 예다.
>>> minmax([92, -21, 0, 104, 51, 76, -92])
[-92, 104]
>>> minmax(['파', '이', '썬', '프', '로', '그', '래', '밍'])
['그', '프']
연습문제 5-5 산술평균 1
mean() 함수를 정의하라. 이 함수는 시퀀스를 하나 입력받아 시퀀스 내 모든 요소의 산술평균을 반환한다. 단, 빈 시퀀스는 입력하지 않기로 약속한다. 다음은 함수를 호출한 예다.
>>> mean([92, -21, 0, 104, 51, 76, -92])
30.0
힌트: 산술평균을 구하는 방법은 1) 모든 항목의 값을 합하고 2) 항목의 개수만큼 나누는 것이다.
5.2.4 시퀀스 조작 메서드
시퀀스를 조작할 때 많이 사용되는 메서드 몇 가지를 알아보자. 지금 소개하는 메서드는 시퀀스의 내용을 수정하는 메서드이기 때문에 튜플 등의 불변 시퀀스에는 적용할 수 없으며, 가변 시퀀스인 리스트에 주로 사용된다.
| 메서드 | 용도 |
|---|---|
append(x) |
요소 x를 시퀀스의 끝(오른쪽)에 추가한다 |
insert(i, x) |
요소 x를 시퀀스의 i 위치에 삽입한다 |
extend(seq) |
대상 시퀀스를 시퀀스의 끝에 연결한다. |
pop() |
시퀀스의 마지막 요소를 꺼낸다. |
remove(x) |
시퀀스에서 요소 x를 찾아 처음 발견된 것을 제거한다. |
clear() |
시퀀스의 모든 요소를 제거한다 |
표 5-1 시퀀스 조작 메서드
요소 추가, 삽입 메서드
append() 메서드는 매개변수에 전달된 데이터를 시퀀스의 끝에 추가한다.
코드 5-18 append() 메서드 사용하기
>>> numbers = [10, 20, 30, 40]
>>> numbers.append(100) # 시퀀스의 끝에 100을 추가
>>> numbers
[10, 20, 30, 40, 100]
데이터를 시퀀스의 임의의 위치에 삽입할 때는 insert() 메서드를 사용한다.
코드 5-19 insert() 메서드 사용하기
>>> numbers.insert(4, 50) # 시퀀스의 4번 위치에 50을 삽입
>>> numbers
[10, 20, 30, 40, 50, 100]
extend() 메서드는 매개변수로 전달한 시퀀스를 시퀀스 끝에 연결한다. 다른 시퀀스의 모든 요소를 통째로 추가하거나 시퀀스를 합칠 때 사용한다.
코드 5-20 extend() 메서드 사용하기
>>> numbers.extend([101, 102, 103]) # [101, 102, 103] 을 연결한다.
>>> numbers
[10, 20, 30, 40, 50, 100, 101, 102, 103]
extend() 메서드는 += 연산으로 대신해도 된다.
코드 5-21 += 연산은 extend() 메서드와 동일한 결과를 낸다
>>> numbers += [104, 105] # numbers.extend([104, 105]) 와 동일
>>> numbers
[10, 20, 30, 40, 50, 100, 101, 102, 103, 104, 105]
요소 삭제 메서드
pop() 메서드는 시퀀스의 마지막 요소를 삭제하면서 반환도 한다. 마지막 요소를 꺼내 내용을 확인한 후 버리는 동작으로 생각하면 이해하기 쉽다.
코드 5-22 pop() 메서드 사용하기
>>> numbers.pop() # 마지막 요소를 꺼내 확인하고 버린다
105
>>> numbers.pop() # 마지막 요소를 꺼내 확인하고 버린다
104
>>> numbers.pop() # 마지막 요소를 꺼내 확인하고 버린다
103
>>> numbers
[10, 20, 30, 40, 50, 100, 101, 102]
remove(x) 메서드는 특정 요소를 앞에서부터 찾아 처음 발견된 요소를 삭제한다.
코드 5-23 remove() 메서드 사용하기
>>> numbers.remove(40) # 40을 찾아 삭제
>>> numbers
[10, 20, 30, 50, 100, 101, 102]
>>> numbers.remove(99) # 데이터를 찾을 수 없는 경우에는 오류 발생
ValueError: list.remove(x): x not in list
clear() 메서드는 시퀀스의 모든 요소를 삭제한다.
코드 5-24 clear() 메서드 사용하기
>>> numbers.clear()
>>> numbers
[]
연습문제
연습문제 5-6 시퀀스 조작 연습
다음 프로그램을 실행했을 때 화면에 출력되는 결과를 예상해 보아라.
stations = []
stations.append('서울')
stations += (['수원', '대전'])
stations.extend(['밀양', '부산'])
stations.insert(3, '동대구')
print(stations) # 출력 1
print(stations.pop()) # 출력 2
print(stations.remove('수원')) # 출력 3
print(stations) # 출력 4
5.2.5 리스트로 연락처 관리하기
리스트와 시퀀스 연산을 활용해 5.1절에서 발견한 연락처 관리 문제를 해결해 보자.
컬렉션을 사용하지 않았던 코드 5-2에서는 name_1, phone_1, name_2, phone_2, … 하는 식으로 프로그래머가 필요한 연락처 수만큼 변수를 하나하나 정의해야 했다. 저장해야 하는 연락처가 많을 수록 작성해야 하는 코드가 많아지는 데다, 연락처를 몇 개까지 저장해야 하는지가 정해져 있지 않을 때는 더욱 곤란하다.
리스트를 사용하면 이 수많은 변수를 ‘이름 목록’과 ‘전화번호 목록’이라는 두 리스트로 줄일 수 있다. 먼저 이름 목록과 전화번호 목록을 각각 빈 리스트로 정의한다.
코드 5-25 이름 목록과 전화번호 목록 정의
>>> name_list = []
>>> phone_list = []
새 연락처를 추가해야 할 때마다 리스트에 append() 메서드를 적용한다. 이 방법을 사용하면 직접 변수명을 붙일 필요가 없고, 지금까지 저장한 연락처가 몇 개인지 직접 세지 않아도 된다.
코드 5-26 연락처 추가, 연락처 개수 확인
>>> name_list.append('박연오') # 이름 목록에 추가
>>> phone_list.append('01012345678') # 전화번호 목록에 추가
>>> name_list.append('이진수')
>>> phone_list.append('01011001010')
>>> len(name_list) # 저장된 연락처 개수 확인
2
리스트에 저장된 특정 위치의 연락처를 확인할 때는 인덱싱 연산을 사용한다.
코드 5-27 저장된 연락처 확인
>>> name_list[0] + ' ' + phone_list[0] # 0번 연락처 확인
'박연오 01012345678'
컬렉션을 사용함으로써 직접 변수를 정의할 필요가 없어졌고, 데이터를 더 유연하게 관리할 수 있게 되었다. 아직 이름 목록과 전화번호 목록이 하나의 연락처 목록으로 합쳐지지 못하고 구분되어 있다는 점이 신경쓰인다. 이 문제점은 5.4절에서 해결해 볼 것이다.
5.2.6 튜플
튜플은 다양한 데이터를 담을 수 있고 내용을 변경할 수 있는 시퀀스다. 리스트와 비슷하지만 한 번 담은 데이터를 바꿀 수 없다는 점이 다르다. 튜플은 정의될 때부터 담을 데이터가 결정되어야 하고 그 뒤에는 데이터를 추가로 담거나 교체할 수 없다.
튜플 표현하기
튜플을 표현하는 방법은 튜플에 담을 요소가 몇 개인가에 따라 다르다.
- 빈 튜플:
() - 요소가 하나인 튜플:
(1,)또는1, - 요소가 둘 이상인 튜플:
(1, 2)또는1, 2
리스트를 만들 때 [1, 2, 3]처럼 대괄호로 감싸는 것처럼, 튜플을 만들 때는 (1, 2, 3)처럼 괄호로 감싼다. 단, 리스트와는 달리 튜플에서 괄호는 필수가 아니다. 1, 2, 3과 같이 요소를 콤마(,)로 구분해 나열하기만 해도 올바른 튜플 표현이다. 그러나 콤마만으로는 빈 튜플을 표현할 수가 없기 때문에, 빈 튜플은 빈 괄호로 표현한다. 괄호가 필수인 경우는 빈 튜플밖에 없다. 그렇지만 빈 튜플과의 통일성을 지키고 튜플을 식별하기 좋도록 괄호를 붙이는 편이 좋다. 한편, 요소가 하나인 튜플을 작성할 때는 1이나 (1)과 같은 표현은 1이라는 원자 데이터로 인식되므로 (1,)과 같이 끝에 콤마를 붙여주어야 올바른 튜플 표현이다.
튜플은 구성요소를 변경할 수 없는 불변 데이터다. 연락처 목록처럼 수시로 데이터를 변경해야 하는 데이터는 튜플이 아니라 리스트로 작성해야 한다. 튜플은 데이터를 나열하되 그 순서나 내용이 변하지 않을 때 잘 어울린다. 예를 들어, 한 주의 요일 목록(일월화수목금토)은 변하지 않는 개념이므로 튜플로 표현하기에 적합하다.
코드 5-28 한 주를 구성하는 요일을 튜플로 정의
>>> days = ('일', '월', '화', '수', '목', '금', '토') # 튜플 정의하기
>>> days # 튜플 내용 확인
('일', '월', '화', '수', '목', '금', '토')
튜플에 시퀀스 연산 수행하기
튜플도 시퀀스의 일종이다. 리스트와 마찬가지로 시퀀스 연산을 수행할 수 있다.
코드 5-29 튜플의 시퀀스 연산
>>> len(days) # 길이 세기
7
>>> days[0] # 인덱싱 연산
'월'
>>> days[::-1] # 슬라이싱 연산 (새 튜플 생성)
('토', '금', '목', '수', '화', '월', '일')
>>> days + ('천', '해', '명') # 시퀀스 연결 (새 튜플 생성)
('일', '월', '화', '수', '목', '금', '토', '천', '해', '명')
그러나 튜플의 내용을 수정하는 연산은 지원하지 않는다.
코드 5-30 튜플은 내용을 수정하는 연산을 지원하지 않는다
>>> days[1] = '月' # 요소 대입: 지원하지 않음!
TypeError: 'tuple' object does not support item assignment
>>> days.append('천') # append 메서드: 지원하지 않음!
AttributeError: 'tuple' object has no attribute 'append'
5.2.7 레인지
(1, 2, 3, 4, 5, 6, 7, 8)과 같이 등차수열(일정한 간격으로 수를 나열한 것)을 시퀀스로 표현해야 하는 경우가 많다. 그런데 이런 수열의 요소를 직접 입력하는 것은 수열의 범위가 넓을수록 불편하고 실수할 위험이 있다. 레인지(range)를 이용하면 이런 등차수열을 최솟값과 최댓값만으로 표현할 수 있다. ‘레인지’라는 용어는 최솟값과 최댓값의 차이를 뜻하는 통계학 용어에서 따온 것이다.
레인지 표현하기
레인지를 표현할 때는 range() 함수를 사용한다. 이 함수에는 매개변수를 1개 또는 2개 또는 3개 지정할 수 있다. 지정하는 매개변수의 수에 따라서 생성되는 레인지가 다음과 같이 차이가 있다.
range(종료): 0 부터 종료값에 이르기 전의 1씩 증가하는 등차수열 시퀀스를 생성한다.range(시작, 종료): 시작값부터 종료값에 이르기 전의 1씩 증가하는 등차수열 시퀀스를 생성한다.range(시작, 종료, 간격)) 시작값부터, 종료값에 이르기 전의 간격만큼씩 증가하는 등차수열 시퀀스를 생성한다.
range() 함수를 이용해 레인지를 생성해 보자. 레인지는 list() 함수를 이용해 리스트로 변환할 수 있다.
코드 5-31 레인지 표현하기
>>> list(range(9)) # 0 이상, 9 미만의 1씩 증가하는 등차수열
[0, 1, 2, 3, 4, 5, 6, 7, 8]
>>> list(range(5, 12)) # 5 이상, 12 미만의 1씩 증가하는 등차수열
[5, 6, 7, 8, 9, 10, 11]
>>> list(range(0, 20, 2)) # 0 이상, 20 미만의 2씩 증가하는 등차수열
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
레인지는 요소를 필요한 시점에만 만들어낸다
앞의 예에서 레인지를 모두 리스트로 변환해서 내용을 확인했다. range() 함수를 대화식 셸에서 실행해보면, 레인지의 내용이 출력되지 않고 range(0, 9)와 같은 형태의 표현만 반환된다. 레인지의 내용을 확인하려면 list() 함수나 tuple() 함수로 감싸 레인지를 리스트나 튜플로 변환해주어야 한다.
코드 5-32 레인지의 내용은 리스트나 튜플로 변환해야 볼 수 있다
>>> range(9) # 내용 대신 range(0, 9)라는 표현만 출력된다
range(0, 9)
>>> list(range(9)) # 리스트로 변환
[0, 1, 2, 3, 4, 5, 6, 7, 8]
>>> tuple(range(9)) # 튜플로 변환
(0, 1, 2, 3, 4, 5, 6, 7, 8)
레인지의 내용은 왜 바로 출력되지 않을까? 레인지는 요소를 계산하기 위한 규칙만 갖고 있고 요소 자체는 갖고 있지 못하기 때문이다. 레인지는 필요한 요소를 처음부터 미리 다 만들어두는 것이 아니라, 그 요소를 사용해야 하는 시점에 비로소 만들어낸다. 그 덕분에 레인지를 이용하면 ‘0 이상 1 경 미만의 모든 정수’와 같이 매우 넓은 범위의 구간을 정의하는 것도 가능하다. 하지만 이것을 리스트나 튜플로 변환할 때는 오류가 발생할 수도 있으니 주의해야 한다. 다음 실험을 통해 확인해 보자.
코드 5-33 레인지 실험
>>> 경 = 10 ** 16 # 매우 큰 수
>>> range(경) # 규칙만을 정의하므로, 레인지가 즉시 생성된다
range(0, 10000000000000000)
>>> list(range(경)) # 시퀀스 요소를 모두 생성하므로, 메모리가 부족해 오류가 발생한다
MemoryError
>>> range(경)[-1] # 요소 하나를 읽는 것은 문제 없다
9999999999999999
레인지로 큰 범위를 정의하는 것은 문제가 없지만, 그 범위 전체를 리스트나 튜플로 실현하려 하면 메모리가 부족해 오류가 발생할 수 있다.
레인지에 시퀀스 연산 수행하기
레인지는 요소를 직접 갖지 않으므로 요소를 수정하는 것도 당연히 불가능하다. 따라서 레인지는 불변 데이터다. 튜플과 마찬가지로 내용을 수정하는 것을 제외한 시퀀스 연산을 레인지에 적용할 수 있다.
코드 5-34 레인지의 시퀀스 연산
>>> range(0, 100, 2)[10] # 인덱싱 연산
20
>>> range(0, 100, 2)[10:20:2] # 슬라이싱 연산 (새로운 규칙 생성)
range(20, 40, 4)
>>> range(0, 100, 2)[10] = 50 # 요소 대입은 지원하지 않는다.
TypeError: 'range' object does not support item assignment
레인지를 생성한 후 내용을 수정하고 싶다면, 레인지를 리스트로 변환한 후 수정하면 된다.
코드 5-35 레인지를 리스트로 변환한 후에는 수정이 가능하다
>>> numbers = list(range(10))
>>> numbers[5] = 100
>>> numbers
[0, 1, 2, 3, 4, 100, 6, 7, 8, 9]
연습문제
연습문제 5-7 레인지로 계산하기
레인지를 사용해, 0 이상 10000 미만인 모든 짝수의 합계를 구하라.
연습문제 5-8 레인지로 리스트 생성하기
레인지를 사용해, 9부터 0(포함)까지 거꾸로 나열한 리스트를 생성하라.
힌트: 레인지를 리스트로 변환하는 것을 잊지 말자
5.2.8 문자열은 시퀀스다
4.3절에서 문자열 데이터를 소개했다. 문자열은 시퀀스의 일종이다. 리스트와 튜플이 아무 데이터나 요소로 가질 수 있는 것는 반면, 문자열은 개별 문자만을 요소로 가진다. 문자열은 앞 장에서 자세히 설명했다. 여기서는 문자열의 시퀀스로서의 특징만 확인하자.
문자열은 시퀀스이므로 시퀀스 연산이 가능하다. 그러나 불변 데이터이기 때문에 내용을 수정하는 것은 허용되지 않는다.
코드 5-36 문자열의 시퀀스 연산
>>> message = '사막이 아름다운 것은 어딘가에 물을 감추고 있기 때문이야'
>>> '물' in message # 요소가 들어있는지 확인
True
>>> message[17] # 인덱싱 연산
'물'
>>> message[:2] # 슬라이싱 연산
'사막'
>>> message[17] = '샘' # 요소를 바꿀 수는 없다
TypeError: 'str' object does not support item assignment
필요하다면 문자열을 리스트나 튜플로 변환할 수 있다.
코드 5-37 문자열을 리스트, 튜플로 변환하기
>>> list('파이썬')
['파', '이', '썬']
>>> tuple('일월화수목금토')
('일', '월', '화', '수', '목', '금', '토')
join 메서드로 여러 개의 문자열 연결하기
문자열에는 join()이라는 메서드가 있다. 이 메서드는 문자열을 담은 시퀀스를 입력받아, 메서드를 호출한 문자열을 구분자로 하여 시퀀스 속의 문자열들을 하나의 문자열로 연결한다.
코드 5-38 join 메서드로 여러 개의 문자열 연결하기
>>> ''.join(['가난하다고', '외로움을', '모르겠는가']) # ❶
'가난하다고외로움을모르겠는가'
>>> '/'.join(('가난하다고', '외로움을', '모르겠는가')) # ❷
'가난하다고/외로움을/모르겠는가'
>>> '.'.join('가난하다고 외로움을 모르겠는가'.split()) # ❸
'가난하다고.외로움을.모르겠는가'
>>> ' - '.join('일월화수목금토') # ❹
'일 - 월 - 화 - 수 - 목 - 금 - 토'
❶ 빈 문자열('')에서 join() 메서드를 실행하여 인자로 전달된 시퀀스의 문자열을 단순히 이어 붙였다. ❷ '/'을 구분자로 삼아 시퀀스의 각 문자열 사이에 끼워넣어 연결했다. ❸ split() 메서드(4.3절)를 이용하면 문자열을 여러 개의 문자열로 나눈 시퀀스를 구할 수 있는데, 이 시퀀스를 '.'을 구분자로 삼아 연결했다. ❹ 문자열 그 자체도 시퀀스이기 때문에 개별 요소 사이에 구분자(' - ')를 끼워넣을 수 있다.
연습문제
연습문제 5-9 시퀀스 뒤집기
시퀀스를 입력받아 반대 순서로 뒤집어 반환하는 함수 reverse()를 정의하라. 그 후, 이 함수에 리스트, 튜플, 레인지, 문자열을 각각 입력해 결과를 확인해 보아라. 예를 들면 다음과 같다.
>>> reverse([10, 20, 30, 40])
[40, 30, 20, 10]
>>> reverse(tuple('일월화수목금토'))
('토', '금', '목', '수', '화', '월', '일')
>>> reverse(range(10))
range(9, -1, -1)
>>> reverse('파이썬 프로그래밍')
'밍래그로프 썬이파'
힌트: 시퀀스에서 슬라이싱 연산을 수행할 수 있다.
댓글 남기기