11.5 웹으로 정보 주고받기
아, 인터넷. 과거에는 컴퓨터와 외부의 대상 사이에 데이터를 주고받으려면 사람이 직접 손으로 타이핑하거나 디스크를 연결해 정보를 복사해야 했다. 지금은 통신 네트워크를 이용한다. 인터넷은 네트워크들의 네트워크로, 세계 곳곳의 컴퓨터를 서로 연결시켜준다. 인터넷에 비하면 과거의 방식은 말 타고 파발 보내던 시절 같다. 여러 가지 용도로 쓰이지만, 인터넷은 데이터를 교환하기 위한 도구다.
인터넷을 활용한 서비스로는 여러 가지가 있지만 그 중에서도 ‘웹(월드 와이드 웹, WWW)’이 가장 널리 쓰인다. 웹은 인터넷에서 다양한 정보를 서로 연결해 제공하는 정보 환경이다. 여러분도 아마 매일같이 웹 클라이언트(웹 브라우저)로 수많은 웹 서버(웹 사이트)가 제공하는 서비스를 이용해봤을 것이다. 이 때 이용하는 웹 클라이언트 프로그램이나 웹 서비스를 제공하는 프로그램을 만드는 활동을 웹 프로그래밍이라고 한다.
웹 환경은 많은 연구와 사업이 이루어지는 분야이기 때문에 깊이 들어가려면 다뤄야 할 주제가 많다. 이 책에서는 파이썬 라이브러리를 이용해 아주 기초적인 웹 프로그래밍을 체험해 볼 것이다. ‘부록: HTTP 기초’를 참고하면 더 쉽게 이해할 수 있을 것이다.
11.5.1 요청과 응답
웹 브라우저(클라이언트)로 웹 사이트(서버)에 접속할 때 일어나는 일을 순서대로 생각해 보자.
- 사용자가 웹 브라우저의 주소창에 주소를 입력한다.
- 요청: 웹 브라우저는 요청 메시지를 작성해 웹 서버로 발송한다.
- 요청 메시지 전달: 요청 메시지가 인터넷의 복잡한 통신망을 거쳐 웹 서버에 전달된다.
- 응답: 웹 서버는 요청받은 정보를 요청자에게 보낸다.
- 응답 메시지 전달: 응답 메시지가 인터넷의 복잡한 통신망을 거쳐 웹 브라우저에 전달된다.
- 웹 브라우저가 응답 메시지를 해석해 사용자에게 정보를 출력해준다.
우리가 웹 사이트에 접속할 때마다 이 과정이 수 초 안에 처리된다. 요청 메시지 전달과 응답 메시지 전달은 운영 체제와 인터넷 사업자들이 담당하고 있기 때문에 잘 모르더라도 웹 프로그래밍을 하는 데 큰 문제가 되지는 않는다. 그 대신 요청(request)과 응답(response)을 이해하는 것은 필요하다. 웹 클라이언트가 되어 웹 서버에 요청해보고, 웹 서버가 되어 웹 클라이언트의 요청에 응답해 보자.
11.5.2 웹 클라이언트로서 정보 요청하기
요청이란 일정한 약속(HTTP)에 따라 클라이언트(서비스 이용자)가 서버(서비스 제공자)에게 특정 주소(URL)에 해당하는 정보를 달라고 메시지를 보내는 것이다. 정보를 요구하는 입장에서는 요청만 제대로 할 줄 알면 된다.
요청을 해서 웹 환경에 공개된 자원에 접근할 수 있다. 이 때 자원이란 웹 문서 뿐 아니라 이미지·음악·영상 등 여러 가지 형태의 정보를 통틀어 말하는 것이다. 단순히 자원을 조회하는 것 뿐 아니라, 로그인·글 올리기·인터넷 쇼핑 등 다양한 일이 모두 요청을 통해 이루어진다.
파이썬으로 웹 요청을 수행하는 것은 여러분이 평소 웹 브라우저로 웹 사이트에 접속하는 것과 똑같다. 차이가 있다면, 주소를 입력하는 곳이 주소창이 아니라 함수의 매개변수라는 것 정도다. 웹 공간에 존재하는 수많은 자원은 https://python.bakyeono.net과 같은 형식의 주소로 식별한다. 이 식별자를 ‘URL(Uniform Resource Locator)’이라고 한다. 어떤 자원의 URL을 알면, 파이썬으로 그 자원을 요청할 수 있다.
웹에 정보 요청하기
파이썬은 URL과 웹 요청에 관련된 모듈들을 urllib(URL 관련 라이브러리라는 의미)이라는 패키지로 묶어 제공한다. 두 가지 모듈만 알면 HTTP 요청을 할 수 있다.
urllib.parse: URL 해석·조작 기능을 담은 모듈urllib.request: HTTP 요청 기능을 담은 모듈
urllib.request 모듈의 HTTP 요청 기능부터 살펴보자. urllib.request 모듈을 임포트한 후, urllib.request.urlopen(요청할URL).read().decode('utf-8') 이라는 표현을 실행하면 웹 요청을 보낼 수 있다. 명령이 조금 길어 어렵게 느껴질 듯하다. 명령이 긴 이유는 다음과 같은 중간 과정을 처리해야 하기 때문이다.
urllib.request.urlopen()함수는 웹 서버에 정보를 요청한 후, 돌려받은 응답을 저장하여 ‘응답 객체(HTTPResponse)’를 반환한다.- 반환된 응답 객체의
read()메서드를 실행하여 웹 서버가 응답한 데이터를 바이트 배열로 읽어들인다. - 읽어들인 바이트 배열은 이진수로 이루어진 수열이어서 그대로는 사용하기 어렵다. 웹 서버가 응답한 내용이 텍스트 형식의 데이터라면, 바이트 배열의
decode('utf-8')메서드를 실행하여 문자열로 변환할 수 있다. 이 때 ‘utf-8’은 유니코드 부호화 형식의 한 종류인데decode()함수의 기본 인자이므로 생략해도 된다.
이것을 매번 입력하기 귀찮다면 다음과 같이 함수로 정의해두는 것도 좋은 생각이다.
코드 11-77 웹 문서 요청 함수 정의해 두기
import urllib.request
def request(url):
"""지정한 url의 웹 문서를 요청하여, 본문을 반환한다."""
response = urllib.request.urlopen(url)
byte_data = response.read()
text_data = byte_data.decode('utf-8')
return text_data
웹 요청이 필요할 때마다 이 페이지를 펼쳐 보고 따라 입력해도 된다. 여러 번 하다 보면 저절로 익혀진다. 다음은 이 책을 소개하는 웹 사이트 https://python.bakyeono.net에 접속(요청)해 본 예다. 따라 입력해보기 바란다. 요청을 실행했을 때 인터넷 연결이 원활하지 않거나, URL이 잘못되었다면 예외가 발생할 수 있다.
코드 11-78 웹 문서 요청하기
>>> import urllib.request
>>> url = 'https://python.bakyeono.net' # 요청할 URL
>>> webpage = urllib.request.urlopen(url).read().decode('utf-8')
>>> print(webpage) # 응답 받은 텍스트 확인: HTML 문서가 출력된다
<!DOCTYPE html>
<html>
... (뭔가 복잡한 내용이 출력된다) ...
</html>
웹 문서의 형식
요청한 결과로 서버가 응답해 준 텍스트를 print() 함수로 출력해 살펴보자. 뭔가 이해하기 힘든 복잡한 텍스트가 화면을 가득 메울 것이다. 이것은 HTML(HyperText Markup Language)이라는 언어로 작성된 문서다. 웹 브라우저로 접속했을 때 전달받는 문서와 동일한 문서다. 웹 브라우저는 HTML 문서를 사람이 보기 좋게 가공하여 출력해 주지만, 파이썬 표준 라이브러리는 그렇게 해 주지 않는다. 그래서 모양이 날 것의 HTML 문서는 생소해 보일 수 있다. 웹 브라우저에서도 ‘소스 보기’ 기능을 이용해보면, 가공되지 않은 HTML 문서를 볼 수 있다.
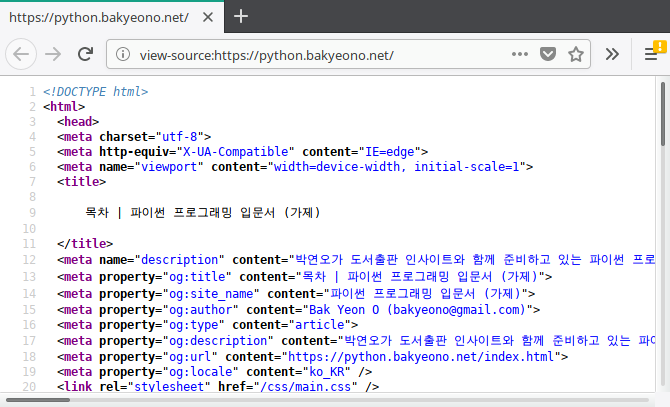
그림 11-2 웹 브라우저로 HTML 문서 ‘소스 보기’
웹의 정보를 굳이 웹 브라우저가 아니라 파이썬에서 읽어들인다면, 그 목적은 읽어들인 정보를 프로그램으로 처리하기 위한 것이다. HTML 문서는 웹 브라우저로 보기에는 편리하지만, 엄격하게 형식화되지는 않았기 때문에 프로그램으로 해석하고 처리하기가 까다로운 편이다. 웹에는 프로그램에서 다루기 편리한 편리한 형식으로 제공되는 정보도 많이 있다. 그런 형식의 한 예가 JSON이다. 웹 브라우저로 https://python.bakyeono.net/data/movies.json에 접속해 JSON 형식의 데이터를 열람해 보자.
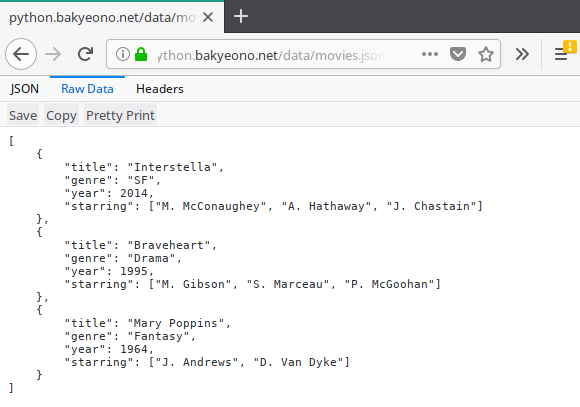
그림 11-3 웹의 JSON 데이터를 웹 브라우저로 열기
이 데이터를 파이썬 대화식 셸에서도 읽어들여서 웹 브라우저로 받은 것과 비교해 보자. urllib.request.urlopen() 함수로 위의 URL에 요청하면 된다.
코드 11-79 웹에서 JSON 데이터 읽어들이기
>>> url = 'https://python.bakyeono.net/data/movies.json' # 요청할 주소
>>> text_data = urllib.request.urlopen(url).read().decode('utf-8')
>>> print(text_data)
[
{
"title": "Interstella",
"genre": "SF",
"year": 2014,
"starring": ["M. McConaughey", "A. Hathaway", "J. Chastain"]
},
{
"title": "Braveheart",
"genre": "Drama",
"year": 1995,
"starring": ["M. Gibson", "S. Marceau", "P. McGoohan"]
},
{
"title": "Mary Poppins",
"genre": "Fantasy",
"year": 1964,
"starring": ["J. Andrews", "D. Van Dyke"]
}
]
웹 브라우저와 마찬가지로 JSON 데이터가 응답되었다. JSON 데이터는 json.loads() 함수를 이용해 파이썬 컬렉션으로 해석할 수 있다.(11.5절) 다음과 같이 컬렉션으로 해석해 두고, 데이터를 원하는 대로 이용할 수 있다.
코드 11-80 웹에서 받은 JSON 데이터 해석·가공하기
>>> import json
>>> movies = json.loads(text_data)
>>> sorted_by_year = sorted(movies, key = lambda movie: movie['year'])
>>> for movie in sorted_by_year:
... print(str(movie['year']) + ' ' + movie['title'].upper())
...
1964 MARY POPPINS
1995 BRAVEHEART
2014 INTERSTELLA
이상으로 웹의 정보를 요청하는 기본 방법을 알아보았다. 겨우 한 행 짜리 파이썬 명령으로 웹에서 정보를 요청할 수 있다. 복잡한 인터넷 통신 과정은 파이썬 라이브러리, 운영 체제, 네트워크 인프라가 대신 처리해 준다. 웹에서 데이터를 수집하는 방법을 더 자세히 알고 배우고 싶다면 『파이썬으로 웹 크롤러 만들기』(라이언 미첼 저, 한선용 역, 한빛미디어)를 읽어보면 많은 도움이 될 것이다.
11.5.3 URL 다루기
URL은 인터넷 공간에 존재하는 자원을 가리키기 위한 절대 주소다. URL을 작성하는 양식은 다음과 같이 정해져 있다.
프로토콜://계정:패스워드@호스트:포트번호/하위경로?질의조건#색인
이 양식에서 가장 자주 사용되는 요소는 프로토콜, 호스트, 하위 경로다. 그 외의 요소는 생략될 때가 많다.
- 프로토콜: 자원에 접근하기 위한 통신 방법을 나타낸다. 웹에서는
http와https가 사용된다. HTTPS는 HTTP에 SSL이라는 암·복호화 단계를 적용하여 보안 통신을 수행하는 프로토콜이다. - 호스트: 자원이 위치한 네트워크(또는 컴퓨터)의 도메인 주소 또는 IP 주소.
- 하위 경로: 한 호스트는 여러 개의 자원을 제공할 수 있다. 그 하위 자원을 가리키기 위해 호스트 이름 뒤에
/wiki/Python_(programming_language)와 같이 표기한다. - 질의조건: 자원을 조회할 때 선택적으로 입력하는 세부 조건이다. 예를 들어, 동일한 자원이 여러 페이지로 나뉘어있는 경우에 세 번째 페이지를
?page=3과 같은 형식으로 표기할 수 있다.
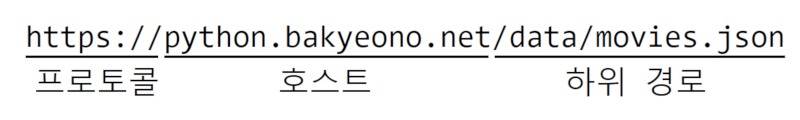
그림 11-4 URL 구성의 예
URL 분할·수정·재결합
파이썬에서 URL을 조작할 때는 urllib.parse 모듈을 사용한다. 이 모듈의 함수 urllib.parse.urlsplit()를 이용하면 URL을 여러 부분으로 나눌 수 있다.
코드 11-81 URL을 여러 부분으로 나누기
>>> import urllib.parse
>>> url = https://python.bakyeono.net/data/movies.json
>>> url_parts = urllib.parse.urlsplit(url) # URL 나누기
>>> url_parts[0] # 프로토콜 확인
'https'
>>> url_parts[1] # 호스트 확인
'python.bakyeono.net'
>>> url_parts[2] # 하위 경로 확인
'/data/movies.json'
urllib.parse.urlsplit() 함수는 나눈 URL 부분들을 튜플에 담아 반환한다. URL의 각 부분을 수정하려면 튜플을 리스트로 변경해 두어야 한다. 수정을 마친 후 다시 하나의 URL로 합칠 때는 urllib.parse.urlunsplit() 함수를 사용하면 된다. 다음 코드는 나눈 URL에서 하위 경로를 수정한 후 다시 합쳐 본 것이다.
코드 11-82 나눈 URL을 수정한 뒤 다시 합치기
>>> url_parts = list(url_parts)
>>> url_parts[2] = '/chapter-11.html'
>>> urllib.parse.urlunsplit(url_parts)
'https://python.bakyeono.net/chapter-11.html'
퍼센트 인코딩
URL에 사용할 수 있는 문자는 영문자, 숫자, 몇몇 기호 뿐이다. 그 밖의 문자(한글·한자·특수문자 등)는 사용할 수 없다. 위키백과의 파이썬 문서를 가리키는 https://ko.wikipedia.org/wiki/파이썬이라는 URL을 urllib.request.urlopen() 함수로 요청하면 ‘파이썬’이라는 한글 때문에 오류가 발생한다.
코드 11-83 URL에 한글이 섞여 있으면 요청할 때 오류가 발생한다.
>>> urllib.request.urlopen('https://ko.wikipedia.org/wiki/파이썬')
UnicodeEncodeError: 'ascii' codec can't encode characters in position 10-12: ordinal not in range(128)
이를 피하기 위해서는 URL에서 아스키 코드가 아닌 문자들을 퍼센트 인코딩(percent encoding)이라는 형식으로 바꾸어야 한다. 우리가 사용하는 웹 브라우저는 퍼센트 인코딩을 자동으로 수행해준다. 파이썬에서는 urllib.parse.quote() 함수로 한글 텍스트를 퍼센트 인코딩으로 변환한 문자열을 구할 수 있다.
코드 11-84 한글 텍스트를 퍼센트 인코딩하기
>>> urllib.parse.quote('파이썬')
'%ED%8C%8C%EC%9D%B4%EC%8D%AC'
퍼센트 인코딩된 텍스트를 다시 일반 텍스트로 되돌릴 때는 urllib.parse.unquote() 함수를 사용한다.
코드 11-85 퍼센트 인코딩된 텍스트를 되돌리기
>>> urllib.parse.unquote('%ED%8C%8C%EC%9D%B4%EC%8D%AC')
'파이썬'
URL에서 한글이 포함된 부분을 퍼센트 인코딩하여 요청하면, 요청이 정상적으로 수행된다.
코드 11-86 URL에 한글이 들어간 문서 요청하기
>>> base_url = 'https://ko.wikipedia.org'
>>> path = urllib.parse.quote('/wiki/파이썬')
>>> url = base_url + path
>>> urllib.request.urlopen(url).read().decode('utf-8')
(요청에 성공하여 HTML 문서가 화면에 출력된다. 출력 결과 생략.)
11.5.4 웹 서버로서 정보 제공하기
이번에는 웹 서버의 역할이 되어, 웹 클라이언트의 요청이 오기를 기다리다가 요청이 왔을 때 적절한 응답을 하도록 해 보자.
웹 서버 프로그램의 실행 과정
웹 서버 프로그램이 어디에선가 들어온 요청을 받아 응답하기까지 거치는 절차를 단순히 정리해 봤다.
- 수신 대기(listen): 클라이언트의 요청이 오기를 기다린다.
- 중계(route): 요청을 받으면, 요청 메시지(URL, 메서드 등)를 해석하여 그에 해당하는 기능(함수)을 호출한다.
- 실행: 중계 과정에서 호출된 기능을 실제로 처리한다. 이 과정에서 데이터베이스 시스템과 같은 프로그램 외부의 자원을 활용하기도 한다.
- 출력 결과 가공(render): 실행된 결과를 일정한 형식으로 가공한다. 이 과정에서 템플릿(미리 준비한 양식에 세부사항을 채워넣는 방법) 도구를 활용하기도 한다.
- 응답: 실행된 결과를 클라이언트에게 되돌려준다.
복잡한 웹 서버 프로그램은 위의 각 절차마다 수많은 세부 절차를 수행한다. 하지만 지금은 웹 서버가 어떤 일을 하는지 느껴볼 정도로만 간단하게 구현해 볼 것이다.
간단한 웹 서버 만들기
표준 라이브러리를 이용해 간단한 웹 서버를 만들 수 있다. http.server 모듈에 웹 서버를 만들 때 필요한 기능이 들어 있다.
http.server.HTTPServer: 통신 채널을 열고, 클라이언트의 요청을 수신 대기하는 클래스. HTTP 프로토콜보다 낮은 수준에서 통신 과정을 처리해준다.http.server.BaseHTTPRequestHandler: 요청받은 내용을 해석하여 처리하기 위한 뼈대 클래스. 이 클래스를 확장해 중계·실행·응답 내용을 정의할 수 있다.
코드 11-87은 이 두 클래스를 이용해 간단한 웹 서버를 구현한 것이다.
코드 11-87 GET 요청을 처리해주는 간단한 웹 서버
import http.server
class HTTPRequestHandler(http.server.BaseHTTPRequestHandler):
"""HTTP 요청을 처리하는 클래스"""
def do_GET(self): # ❶
"""HTTP GET 요청을 처리한다."""
self.route()
def route(self): # ❷
"""요청 URL의 path에 따라 요청을 처리할 함수를 중계한다."""
if self.path == '/hello':
self.hello()
else:
self.reponse_404_not_found()
def hello(self): # ❸
"""200 OK 상태 코드와 인삿말을 응답한다."""
self.response(200, '안녕하세요?')
def reponse_404_not_found(self): # ❹
"""404 Not Found 상태 코드와 오류 메시지를 응답한다."""
self.response(404, '요청하신 문서를 찾을 수 없습니다.')
def response(self, status_code, body): # ❺
"""응답 메시지를 전송한다."""
# 상태 코드 전송
self.send_response(status_code)
# 헤더 전송
self.send_header('Content-type', 'text/plain; charset=utf-8')
self.end_headers()
# 본문 전송
self.wfile.write(body.encode('utf-8'))
# 요청받을 주소 (요청을 감시할 주소)
ADDRESS = 'localhost', 8000
# 요청 대기하기
listener = http.server.HTTPServer(ADDRESS, HTTPRequestHandler) # ❻
print(f'http://{ADDRESS[0]}:{ADDRESS[1]} 주소에서 요청 대기중...')
listener.serve_forever() # ❼
요청을 받았을 때 실행할 동작을 http.server.BaseHTTPRequestHandler 클래스를 확장해 정의했다. ❶ do_GET() 메서드는 미리 정의하도록 약속된 메서드다. 클라이언트가 GET HTTP 메서드로 요청을 보냈을 때 저절로 호출된다. 이 외의 나머지 메서드는 임의로 정의한 것이다. ❷ route() 메서드는 요청한 URL의 하위 경로(self.path)에 따라 적절한 함수를 실행하도록 중계한다. ❸ hello() 메서드는 실행과 출력 결과 가공을 맡는 역할을 할 수 있는데, 프로그램이 단순해서 별다른 일은 하지 않는다. 그냥 정상적인 응답을 뜻하는 200 상태 코드와 인삿말을 응답한다. ❹ reponse_404_not_found() 메서드는 사용자가 요청한 문서가 존재하지 않음을 뜻하는 404 상태 코드와 오류 메시지를 응답한다. ❺ response()는 실제로 응답을 수행하는 메서드다. HTTP 응답 메시지 규칙에 따라 상태 코드, 헤더, 본문을 순서대로 출력한다. 자세한 내용은 부록을 참고하기 바란다.
❻ http.server.HTTPServer 클래스를 인스턴스화하여 서버 인스턴스를 생성할 수 있다. 인자로는 이 서버가 요청을 받은 주소와 요청을 처리할 처리기(위에서 정의한 HTTPRequestHandler)를 전달한다. ❼ 서버 인스턴스의 serve_forever() 메서드를 실행하면 서버가 실행되고 클라이언트의 요청을 계속 기다린다. 요청이 오면 HTTPRequestHandler.do_GET()에 정의한 대로 적절히 응답도 해 준다. 서버의 실행을 중지하려면 Ctrl+C 키를 누르면 된다.
서버 프로그램을 실행하고, 웹 브라우저의 주소 창에 http://localhost:8000/hello라는 URL을 입력해 접속해 보자. 인사가 잘 출력되는가? 비록 매우 단순하지만, 이 프로그램은 다른 웹 서버가 요청을 받아 응답하는 절차와 크게 다르지 않다. 그림 파일을 제공하는 웹 서버는 요청된 파일의 경로를 URL에서 확인하여 서버에서 읽어들여 그 내용을 응답한다. 위의 웹 서버 프로그램에 그림 파일을 읽어들여 내보내는 기능을 추가하면 그런 기능을 만들 수 있다. 게시판을 서비스하는 웹 서버는 사용자가 업로드한 정보를 데이터베이스에 저장해 두었다가 사용자가 요청했을 때 데이터베이스의 내용을 읽어 응답한다. 웹 서버에 데이터베이스 또는 파일에 정보를 읽고 쓰는 기능을 연동하면 게시판 서비스도 만들 수 있다.
실무에서는 웹 프레임워크(web framework)(웹 서버 프로그램의 뼈대와 부가 기능을 미리 만들어 놓은 라이브러리)를 이용해 웹 서버를 개발할 때가 많다. 웹 사이트·웹 서버를 제대로 만들어보고 싶다면 파이썬 웹 프레임워크인 ‘장고(Django)’를 배워보기를 권한다. 교재로는 『파이썬 웹 프로그래밍: 장고로 배우는 쉽고 빠른 웹 개발』(김석훈 저, 한빛미디어)과 『장고 걸스 튜토리얼』(https://tutorial.djangogirls.org)을 추천한다.
댓글 남기기